
See all blog posts in this series:
- From VMware to IBM Cloud VPC VSI, part 1: Introduction
- From VMware to IBM Cloud VPC VSI, part 2: VPC network design
- From VMware to IBM Cloud VPC VSI, part 3: Migrating virtual machines
- From VMware to IBM Cloud VPC VSI, part 4: Backup and restore
- From VMware to IBM Cloud VPC VSI, part 5: VPC object model
- From VMware to IBM Cloud VPC VSI, part 6: Disaster recovery
- From VMware to IBM Cloud VPC VSI, part 7: Automation
- From VMware to IBM Cloud VPC VSI, part 8: Veeam Backup and Replication
If you consider the VPC object model, it is clear that to deploy and manage a large-scale environment, you need to consider the use of automation. Your operational challenge is further multiplied if you are planning for disaster recovery and intend to replicate or re-create your VPC environment from one region to another.
I’ve created a relatively simple set of Terraform modules with the goal of demonstrating how to:
- Deploy a simple two-tier autoscaling application to one IBM Cloud region;
- Create a skeleton VPC network topology for this application in a second IBM Cloud region, in preparation for disaster recovery;
- Replicate application data from the first region to the second region; and
- Failover the application to the second region in case of a disaster
Application design
My two-tier application is a toy application. It consists of:
- An IBM Cloud regional application load balancer; in front of
- A set of three or more autoscaling application VSIs spread across the three zones of the region; connected to
- A pair of primary-standby database VSIs spread across the first two zones of the region
The “application” running in the first tier is simply SSH. The VSIs share a common SSH host key much like you would share a certificate among a web application.
The database is PostgreSQL configured in streaming replication mode. The “application” connection to the database is simply by means of the psql command. The database is configured to allow direct connection from the application VSIs without password.
Apply complete! Resources: 76 added, 0 changed, 0 destroyed.
Outputs:
region1_lb_hostname = "2e3d3210-us-east.lb.appdomain.cloud"
region2_lb_hostname = "5532cedf-ca-tor.lb.appdomain.cloud"
smoonen@laptop ibmcloud-vpc-automation % ssh root@2e3d3210-us-east.lb.appdomain.cloud
Welcome to Ubuntu 24.04.3 LTS (GNU/Linux 6.8.0-1041-ibm x86_64)
. . .
root@smoonen-tier1-tlha2hqzy6-lrioe:~# psql -h db-primary.example.com testdb appuser
psql (16.11 (Ubuntu 16.11-0ubuntu0.24.04.1))
testdb=> \dt
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | test_replication | table | postgres
(1 row)
Failover within the primary region of the primary database server is beyond the scope of this test. You would need to develop your own automation or administrative process to manage the PostgreSQL failover and the DNS reassignment.
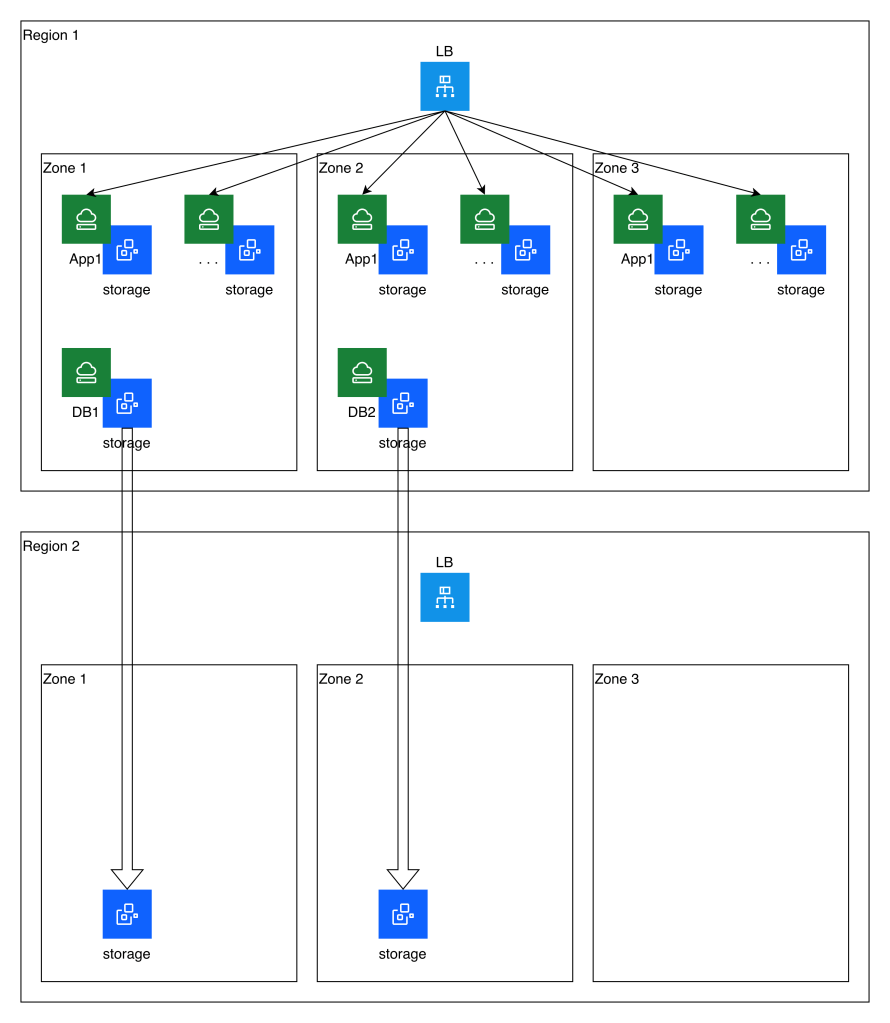
The following diagram illustrates the application topology as well as the storage replication that is established to a secondary region:
Replication
As we discussed previously, this automation leverages block storage snapshots and cross-region copies as a simple approach to replication. This imposes some limitations, including a lack of write-order consistency between volumes, and RPO constraints. This simple example has volumes that can be copied at hourly intervals, but a real-world example is likely to have a longer RPO.
Because of the lack of write-order consistency, in this model you would need to assess which of the two databases had won the race and should be reconstituted as the primary database server. If you were storing and replicating application data (for example, transaction logs stored on IBM Cloud VPC file storage which is also being replicated to the secondary region) you would need to perform a similar analysis of consistency before completing the recovery process.
In this example, since the application servers are stateless, their storage is not replicated to the secondary region. They can be re-created purely from their definition.
Failover
You can see from the diagram above that no running infrastructure other than the load balancer exists in the secondary region during steady-state replication. Upon failover, this example leverages an additional Terraform module to identify the most recent copied storage snapshot and re-create the instances and instance groups for the application and database servers.
Details
Refer to the documentation in the GitHub repository for additional instructions and considerations.
